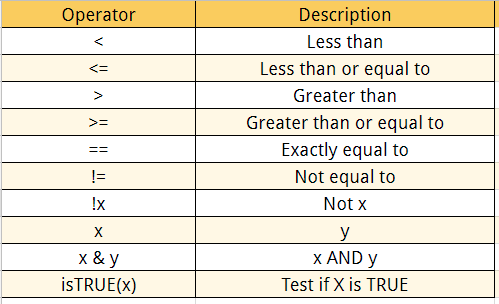
In the following coding examples, you will see three important functions, a pipe, select(), and filter(). First, a pipe is written as a %>% or |>. Pipes are a powerful tool that help us clearly expressing a sequence of functions. Pipes tell R that you want to use a designated set for a chain of functions that build off of each other. A way to think about is in math terms.
$$
\[ F(G(H(X))), X=Data\]
$$
In this series of functions, the first step is you solve \(H(X)\), then using that solution you solve \(G()\), then after you solve \(F()\). The final output is the solution of those chain of events with the information of \(X\). This is how pipes work! Pipes use a set of information, typically a data frame, and then apply it to a series of functions that build off each other.
In the following example, I use the select() and filter() to simplify the data. The select() allows me to select certain variables from the data and eliminate the rest. filter() does something similar but instead of variables, it allows me to simplify the data based on values based on a set of programmed logical operators. In my first example, I select for the circuit, year, constructor, surname of the driver, and the number of points awarded during that race. I use the unique() to remove duplicates, and then I filter for the race information for the constructor McLaren during the 2023 season.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.1.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
# A tibble: 40 × 5
circuit year constructor surname points
<chr> <dbl> <chr> <chr> <dbl>
1 Bahrain International Circuit 2023 McLaren Norris 0
2 Jeddah Corniche Circuit 2023 McLaren Norris 0
3 Jeddah Corniche Circuit 2023 McLaren Piastri 0
4 Albert Park Grand Prix Circuit 2023 McLaren Norris 8
5 Albert Park Grand Prix Circuit 2023 McLaren Piastri 4
6 Baku City Circuit 2023 McLaren Norris 2
7 Baku City Circuit 2023 McLaren Piastri 0
8 Miami International Autodrome 2023 McLaren Norris 0
9 Miami International Autodrome 2023 McLaren Piastri 0
10 Circuit de Monaco 2023 McLaren Norris 2
# ℹ 30 more rows
What if we wanted two different constructors? Then we want to use the logical operator for | and also differentiate it from the next instruction for filter by using a , or (). In the example bellow, I filter for the race information for the constructor Mercades and Red Bull during the 2021 season.
# A tibble: 40 × 5
circuit year constructor surname points
<chr> <dbl> <chr> <chr> <dbl>
1 Losail International Circuit 2021 Red Bull Pérez 12
2 Losail International Circuit 2021 Red Bull Verstappen 19
3 Bahrain International Circuit 2021 Red Bull Pérez 10
4 Bahrain International Circuit 2021 Red Bull Verstappen 18
5 Autodromo Enzo e Dino Ferrari 2021 Red Bull Pérez 0
6 Autodromo Enzo e Dino Ferrari 2021 Red Bull Verstappen 25
7 Autódromo Internacional do Algarve 2021 Red Bull Pérez 12
8 Autódromo Internacional do Algarve 2021 Red Bull Verstappen 18
9 Circuit de Barcelona-Catalunya 2021 Red Bull Pérez 10
10 Circuit de Barcelona-Catalunya 2021 Red Bull Verstappen 19
# ℹ 30 more rows
However, if we wanted to use the modified data, we could not because it is not saved. If we want to use this data we need to save it as a new object!
# A tibble: 40 × 5
circuit year constructor surname points
<chr> <dbl> <chr> <chr> <dbl>
1 Losail International Circuit 2021 Red Bull Pérez 12
2 Losail International Circuit 2021 Red Bull Verstappen 19
3 Bahrain International Circuit 2021 Red Bull Pérez 10
4 Bahrain International Circuit 2021 Red Bull Verstappen 18
5 Autodromo Enzo e Dino Ferrari 2021 Red Bull Pérez 0
6 Autodromo Enzo e Dino Ferrari 2021 Red Bull Verstappen 25
7 Autódromo Internacional do Algarve 2021 Red Bull Pérez 12
8 Autódromo Internacional do Algarve 2021 Red Bull Verstappen 18
9 Circuit de Barcelona-Catalunya 2021 Red Bull Pérez 10
10 Circuit de Barcelona-Catalunya 2021 Red Bull Verstappen 19
# ℹ 30 more rows